

Data Quality Metrics for Data Warehouses (or: KPIs for KPIs)
This article is primarily for data practitioners who want to improve the quality of data in their databases and data warehouses, but also for professionals whose work impacts data quality (looking at you, software engineers and sales people) or is affected by poor data quality.
The goal is to give you a framework for thinking about data quality metrics and a process for identifying which metrics your team should use. By the end of this article, you should leave with a sense of which metrics you should track to improve the quality of your data.


Why does monitoring data quality matter?
If a dataset lands in a warehouse and no one uses it, does it even matter? Data exists to be used, whether it is sales data for operationalization into a sales tool, product data for training a machine learning model, or financial data for decision-making with business intelligence (BI) dashboards.
The first requirement for data to be used is to, well, have data. The second requirement is to have literacy for working with data. The third requirement is to have trust in data. If your stakeholders do not trust your data, they will not only refrain from using it now, but can be turned off from data in perpetuity.
Enter data quality, the umbrella term encompassing all of the factors that influence whether data can be relied upon for its intended use. If you’ve worked in the data industry, you know that data quality matters. You might also believe that improving data quality is a Sisyphean task of pushing a boulder up a hill just to have it roll back down. The bad news is that you’ll always be pushing that boulder. Sorry. The good news is that, with the right metrics, strategies, and processes, that boulder can get smaller, you can get stronger, and the hill can get shallower.
As someone who works with data, you don’t need to be told that the most effective way to improve something is to measure it. Not just profiling at one point in time, or before and after an intervention, but continuously monitoring. That’s where the dimensions and metrics of data quality become relevant: they are the dials and charts on your data quality dashboard.
Introduction to data quality dimensions and metrics
Data quality is a topic as old as data itself. Luckily for us, that means we can draw on decades of written experience from researchers and industry practitioners. Specifically, this piece leans on literature from different fields such as data quality management, data quality measurement, and information quality.
Across these fields, one key concept is the different dimensions of data quality, which are categories along which data quality can be grouped. These dimensions can then be instantiated as metrics of data quality, also referred to as database quality metrics or data warehouse metrics depending on where the data resides, that are specific and measurable. (Sebastian-Coleman 2013)

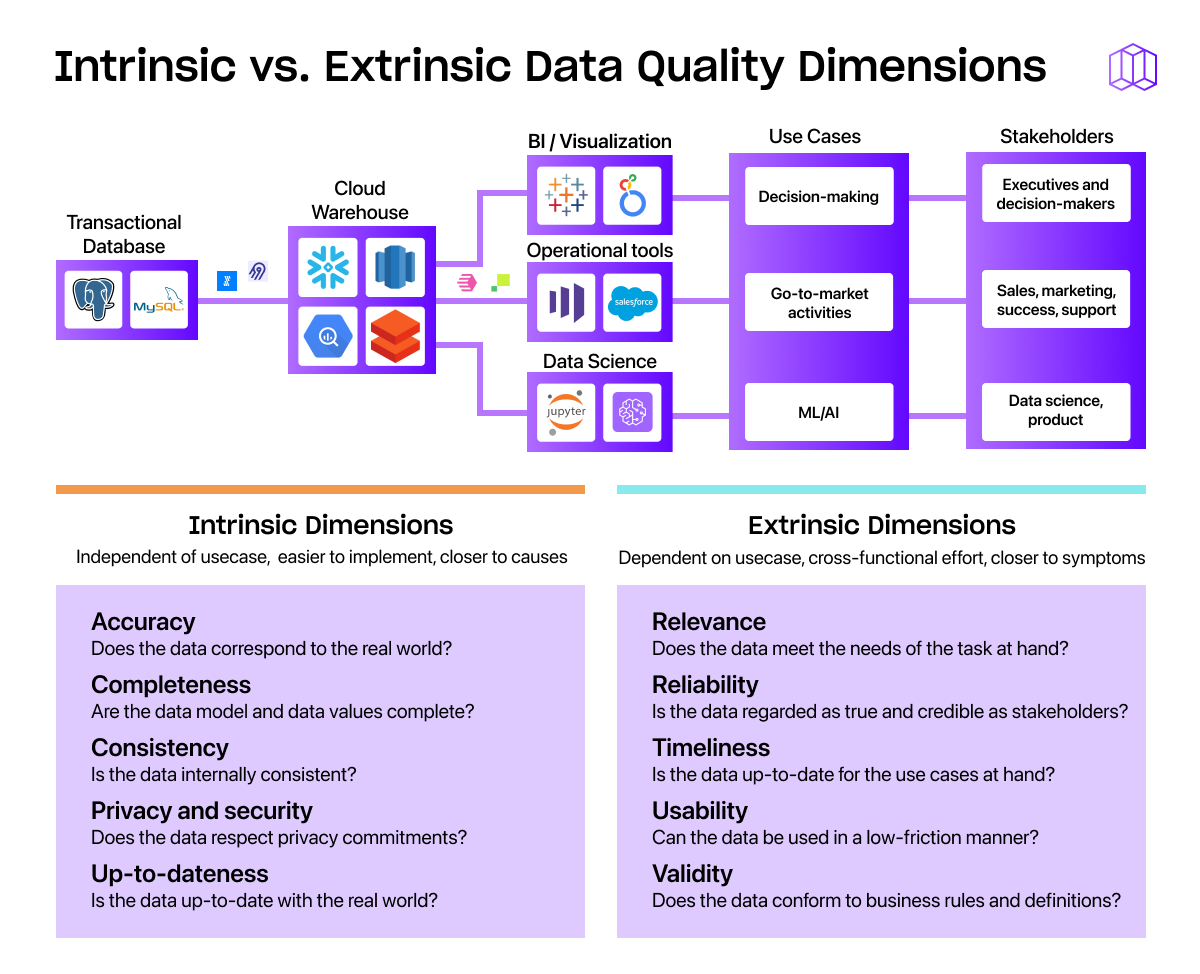
One valuable way to reason about data quality dimensions is to identify whether a dimension is tied to a task or use case. If a dimension is independent of use case, that’s called an intrinsic data quality dimension (or a task-independent dimension). One guiding question is: if the data was never being used, how could we measure its quality? Viewing data as a product, these metrics are like measuring the quality of the product itself, like the amount of technical debt in the code base, the number of internal bugs. (Wang and Strong 1996)
In contrast, an extrinsic data quality dimension (also called a contextual or task-dependent dimension) depends on the use case. A guiding question is: given how the data is used, what measures of quality are most impactful for the use cases at hand? Viewing data as a product again, these metrics are like measuring the amount of downtime in the product, the number of support tickets filed by a consumer, and the average load time for a customer.
Before we dive into the specifics, let’s situate ourselves in an example use case: imagine you’re a lead analytics engineer at Rainforest, an e-commerce company that sells hydroponic aquariums to high-end restaurants. Snowflake is your data warehouse, you use dbt to transform the data into a usable form. When it comes to the data products you produce, you use Looker to create dashboards for decision-makers like the VP of Sales and the C-suite, and use reverse ETL tools to send data to Salesforce to help sales reps trying to reach their quotas for the year.
{{inline-a}}
Intrinsic data quality dimensions
OK, finally we’re onto the data quality dimensions, starting from the intrinsic metrics that are independent of use case. Going back to the fundamentals for a moment, data describes entities in the real world, attributes of those entities, and events that occur in a point in time involving those things that might have attributes themselves. (Wand and Wang 1994) Regardless of how we choose to model the world, a few aspects of data quality come to mind:
Accuracy: Does the data accurately describe the real world? Do the entities actually exist, do they have the attributes you describe in your data model, and do events occur at the times and with the attributes you claim? Accuracy is fractal, so be sure to examine each level of abstraction. (Pipino, Lee, and Wang 2002)
Example problems: The number of aquariums sold this month in the warehouse does not match the actual number sold as reported by the sales people. The geographies assigned to each sales rep is not correct. The dollar value of a specific sale is off by a significant amount.
Metrics to measure: Degree to which your data matches against a reference set (Scannapieco and Catarci 2002), corroborates with other data, passes rules and thresholds that classify data errors (Loshin 2001), or can be verified by humans.
Completeness: How completely does the data describe the real world? There are at least two levels here. First, how complete is your data model? Second, within the data model you’ve constructed, how complete is the data itself?
Example problems: Rainforest’s data warehouse has a table for aquariums, but not for a new product line of subscription fish food. Within the table for aquariums, the new prices of those aquariums are empty.
Metrics to measure: Degree of validation against a complete mapping (Price and Shanks 2005), the number of null data values or data elements or missing data (Loshin 2001, English 2009), the number of satisfied constraints (Loshin 2001), degree of validation against an input mechanism (ISO 2012).
Consistency: Is the data internally consistent? If there are redundant data values, do they have the same value? Or, if values are aggregations of each other, are the values consistent with each other? Codd’s Referential Integrity constraint is one example of a consistency check.
Example problems: The engineering team records aquarium models that don’t match the models recorded by the sales team. The monthly profit number is not consistent with the monthly revenue and cost numbers.
Metrics to measure: Number of passed checks to tracking the uniqueness of values (McGilvray 2008) or uniqueness of entities (Byrne 2008), corroboration within the system, whether referential integrity is maintained (Pipino, Lee, and Wang 2002).
Privacy and security: Is data being used in accordance with the intended level of privacy and secured against undesired access? This is especially important in our world of regular data breaches, and if your company has compliance (e.g. SOC 2) or regulatory (e.g. HIPAA) requirements.
Example problems: Customer billing and location information is stored in the warehouse and each member of the data science team is able to query that personal data. Access to the warehouse isn’t reviewed on a regular basis and is not granted according to the principle of least privilege.
Metrics to measure: Number of sensitive data values available to database users, number of database users who should not have access, amount of unmasked sensitive data.
Freshness: Does the data describe the real world right now? Also called “currency” in the literature (Loshin 2001), this dimension is closely related to the timeliness of the data, but is compared against the present moment rather than the time of a task.
Example problems: The reported number of products sold at Aquarium are one week behind because of a data ingest issue from Salesforce. The list of sales reps is not updated from an internal HR system.
Metrics to measure: Difference between latest timestamps against the present moment, difference from a source system, verification against an expected rate of change (Loshin 2006), corroboration against other pieces of data.
In addition to these main intrinsic data quality dimensions, others include: the integrity of the data, which is often a function of the accuracy, consistency, and completeness of the data; the bias of the data, which is related to accuracy but often tied to skewed outcomes; and conciseness, which describes the amount of redundant data (this is less important in our world of cheap data storage).
Why should you use intrinsic data quality metrics? First, because causes matter. Investing in improving the causes of data quality is a preventative measure and also improves time-to-resolution. Second, they’re typically easier to measure, or at least don’t require collaboration with another team.
Extrinsic data quality dimensions
While intrinsic data quality dimensions can be reasoned about without talking to a stakeholder, extrinsic data quality metrics depend on knowledge of the stakeholder and their use case. These use cases can be analyzed like product requirements: they have a specific purpose, with informal requirements, trust requirements, and a time constraint.
Relevance: Does the available data meet the needs of the task at hand? Do stakeholders require more data than is available to meet their use cases?
Example problems: The support dashboard does not include the latest model purchased by customers. Salesforce does not include the product usage data for sales representatives to properly charge customers.
Metrics to measure: Number of requests to include more data in user-facing systems, number of ad hoc pulls by end users, amount of outstanding work on end user systems, qualitative evaluation asking questions like “do your systems contain all of the data needed for you to do your job?”
Reliability: Is the data regarded as true and credible by the stakeholders? Some factors that impact the reliability of data are: whether the data is verifiable, if there is sufficient information about its lineage, whether there are guarantees about its quality, whether bias is minimized. (Scannapieco and Catarci 2002)
Example problems: The VP of Finance does not trust the data in the quarterly revenue reports. The sales team believes that the product usage data in Salesforce does not reflect the actual usage because of technical issues.
Metrics to measure: Number of requests to verify data in end user systems, amount of certified data products, comprehensiveness of lineage available to end users, bias as measured against a reference set, number of users using the systems.
Timeliness: Is the data up-to-date and made available for the use cases for which it is intended? There are two components here: is the data up-to-date, and what is the delay to make the data available for the stakeholder? For example, the data may be up-to-date within the warehouse, but if the stakeholder isn’t able to use it in time, then the data is not timely.
Example problems: The marketing data is delayed, causing the marketing spend dashboard to lag by a day. Or, a support dashboard relies on expensive queries that take over an hour to complete, making it unusable by the support team to answer immediate calls.
Metrics to measure: Number of passed rules for the latest timestamp in a user-facing system (related to the concept of Service Level Agreements), amount of time required for user-facing systems to retrieve timely data (warehouse-to-destination latency), amount of time required for the entire data infrastructure to propagate values (source-to-destination latency).
Usability: Can be data be accessed and understood in a low-friction manner? Some factors that impact usability are: whether the data is easy to interpret correctly and whether it is unambiguous. (HIQA 2011)
Example problems: The Looker dashboards used by the support team are difficult to interpret. The level of product data available to the sales team is too granular for them to take action.
Metrics to measure: Number of requests to present data in a different way, number of requests to help interpret data, amount of ambiguity as measured by only one interpretation (Kimball and Caserta 2004), number of users using the systems.
Validity: Does the data conform to business rules or definitions?
Example problems: The reported financial numbers are inconsistent between each other. Revenue as recognized by the accounting team relied on different definitions at different points in time.
Metrics to measure: Degree of conformance with business rules (English 2009), number of violations of data in end user systems (Redman 1997), consistency within the data (Loshin 2001), amount of metadata describing the purpose of data (Byrne 2008)
Other extrinsic data quality dimensions include: sufficiency, the degree to which the data sufficient to complete the given task (related to relevance); consistency, similar to the intrinsic dimension but within user-facing systems; ease-of-manipulation, related to the dimension of usability. Like with intrinsic dimensions, each dimension can have quite a lot of overlap.
Why should you use extrinsic data quality metrics? First, because symptoms matter. Investing in improving symptoms is more closely related to the actual business impact being derived from data and also improves time-to-identification. Second, they’re typically easier to align around for another team, because you now share skin in the model.
Putting data quality metrics into practice
Now that we have a list of intrinsic and extrinsic data quality metrics, how do we decide what to measure, how to measure it via data quality rules, and how to make those measurements actionable? We’re preaching to the choir when we say that identifying qualitative KPIs is important, but it’s equally important to operationalize them into numbers that can be tracked over time. Luckily, as a data person, there is no one better than you at tackling those questions systematically. Here’s some guiding principles that we’ve found useful in helping many organizations think about their data quality:
Start from the usecases: What are the most important use cases of data within your organization? You can probably rattle them off, but it’s worth writing them down. At an e-commerce company like Rainforest, it might be sales forecasting for making business decisions during quarterly board meetings and also getting proper data into marketing campaigns. Writing down these use cases connect your data quality metrics to what ultimately matters and informs which stakeholders should be looped in.
Identify the pain points: Within those use cases, what data quality issues have caused the most trouble recently? If the answer is “none,” that’s great! For the rest of us mortals, the answer could be something like: when creating sales forecasts for quarterly board meetings, the data is not refreshed for a subset of customers, the business users have difficulty interpreting the dashboards, and the calculations are not up to date with the latest business metrics.
Connect to data quality dimensions and describe how to measure as metrics: Of the causes of recent trouble, how do they relate to the previous data quality dimensions? In the three previous issues, the first dimension could be up-to-dateness, measured by the mean time difference between the last refresh date of the data within the dashboard and the access time of the dashboard. The second metric could be usability, determined by a quarterly survey of executives answering the question “On a scale from 1-10, how usable was the data in your Looker dashboards”. A third metric could be validity, a measure of the number of outputs shown on the dashboard against a suite of tests independently implementing business rules ranging from simple rules like “the revenue should be greater than 0” to a complex rule like “the net revenue retention is consistent with the total revenue, expansion, and revenue churn numbers.”
Make metrics digestible and actionable: Lastly, how can we make those metrics useful? The Aquarium data team could potentially include those metrics in their raw form in their quarterly Objectives and Key Results (OKRs). The same metrics could be stored within their data warehouse and presented in a dashboard as separate visual elements. Or, towards the idea of a single Data Quality Index (Pipino, Lee, and Wang 2002), the numbers could be aggregated together. For example, the up-to-date metric could be measured on a daily basis, with the difference between (access time) and (update time) exponentiated to penalize slow updates. The usability metric could be the average surveyed usability across all stakeholders. Then the validity metric could be the number of rule violations against a target number. If each of those metrics are normalized, the final DQI could be calculated as the weighted average of those three numbers.

As we walked through that example, you may have wondered “but there’s so many ways to turn these metrics into numbers.” You’re right. There’s no one right way to measure data quality. But we should not let perfect get in the way of the good. Think of the list above like vital signs when going to the doctor’s office, measuring blood pressure, resting heart rate, and so on. The numbers themselves might be useful, but the trend of those numbers may be even more important.
Once you have data quality metrics that you are happy with, keep in mind Goodhart’s Law, which states that “when a measure becomes a target, it ceases to be a good measure.” Even when the metrics trend towards an ideal state, it’s time to consider whether there are other data quality metrics that you could consider that are possibly orthogonal to what you have already established.
Strategies to improve data quality metrics
We said at the beginning that we wouldn’t discuss strategies and processes for improving data quality. There’s just two thoughts we wanted to leave you with. Tolstoy stated that "happy families are all alike; every unhappy family is unhappy in its own way." The same is true for data: high quality data is all alike; low quality data is low quality in its own way. There is no one-size-fits-all approach here, and it’s up to you to decide which problems are the highest priority.
That said, one productive framework for operational improvement within organizations is the People, Process, Technology (PPT) framework:
People: how can your teammates help you develop data quality metrics, hold the organization accountable for meeting those metrics, and play their part in ensuring high quality data? For instance, the engineering organization could implement pull request reviews to minimize breaking changes to upstream systems, impacting the reliability of your downstream data products. You could hire a data quality engineer, data steward, or data governance lead to directly own the implementation and improvement of data quality metrics.
Process: how can your organization implement business processes for data quality improvement? The data team could perform a one-time data quality assessment. Or, for ongoing improvement, the team could implement quarterly OKRs around data quality metrics, metric scorecards, the marketing and sales teams could introduce training initiatives to influence data entry that impacts the data accuracy and data validity, the data team could implement playbooks for remediation.
Technology: how can technologies help improve your data quality metrics? For example, tools like Segment Personas and Iteratively could ensure that product analytics data is consistent and reliable. ELT solutions like Fivetran and Airbyte and Reverse ETL solutions like Hightouch and Census could help ensure that data is both up-to-date and timely. Lastly, there are data quality tools meant for data quality measurement and management, as well as data cleansing tools for fixing data values.
Before we go too far down that direction, remember that you’re taking the proper first step by learning about data quality metrics and being intentional about which ones are most relevant to your specific business. It’s hard to improve what you don’t measure.
Takeaways
- While data quality will always be an issue, defining metrics for data quality helps you know where you stand, improve over time, and align with your team.
- Intrinsic data quality metrics are independent of use case, while extrinsic data quality alerts depend on use case. Intrinsic metrics are easier to define and preventative, while extrinsic metrics are easier to align around and address symptoms.
- Key intrinsic data quality metrics include accuracy, completeness, up-to-dateness, consistency, and privacy + security. Key extrinsic DQ metrics include timeliness, relevance, reliability, usability, and validity.
- You can define which metrics to measure by identifying the key use cases for data in your organization, the issues that arise for those use cases, and selecting metrics that track with those issues.
- People, Process, and Technology are three vectors along which you can begin improving data quality.
- If you'd like to see these metrics play a role in Data Observability, read more here.
Citations and further reading
- Wand and Wang 1994: "Anchoring Data Quality Dimensions in Ontological Foundations"
- Wang and Strong 1996: “Beyond Accuracy: What Data Quality Means to Data Consumers”
- Redman 1997: "Data Quality For The Information Age"
- Loshin 2001: “Enterprise knowledge management: The data quality approach”
- Kimball and Caserta 2004: "The Data Warehouse ETL Toolkit: Practical Techniques for Extracting, Cleaning, Conforming, and Delivering Data"
- Pipino, Lee, and Wang 2002: “Data Quality Assessment”
- Scannapieco and Catarci 2002: “ Data quality under a computer science perspective”
- Loshin 2006: "Monitoring Data Quality Performance Using Data Quality Metrics"
- Byrne 2008: “The information perspective of SOA design”
- McGilbray 2008: “ Executing data quality projects: Ten steps to quality data and trusted information”
- English 2009: “Information quality applied: Best practices for improving business information, processes and systems”
- HIQA 2011: “International Review of Data Quality Health Information and Quality Authority (HIQA)”
- ISO 2012: “ISO 8000-2 Data Quality-Part 2-Vocabulary”
- Sebastian-Coleman 2013: “Measuring Data Quality for Ongoing Improvement”
Table of contents
Tags



...




...
















